Contest About vip.com
Vip.com’s development is so rapidly today. It accumulates many users and goods data. How to predict the needs of customers with these data is one challenging task, and it is the center of practice of big data of Electronic Business.
Our task is predict the probability of buying special good in further one week.
EDA(Exploratory Data Analysis)
Firstly, we explore the distribution of operation(click/buy).
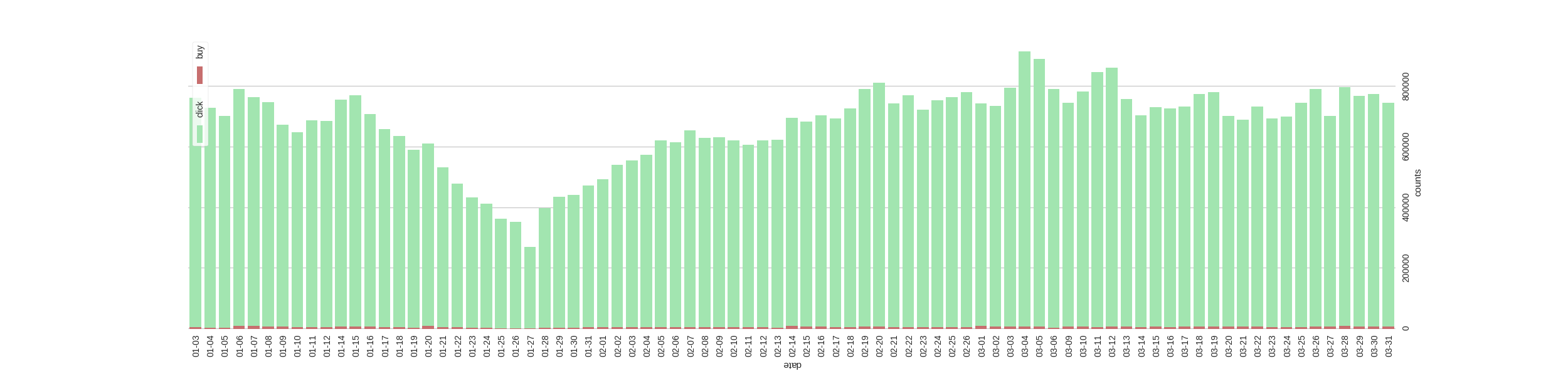
It seems that there are something unusual in 27 January, so we dropout the days before 18 Febrary. At the same time, we can obtain that customs usually click more times than buying :).
So we gather more information of customs and items.
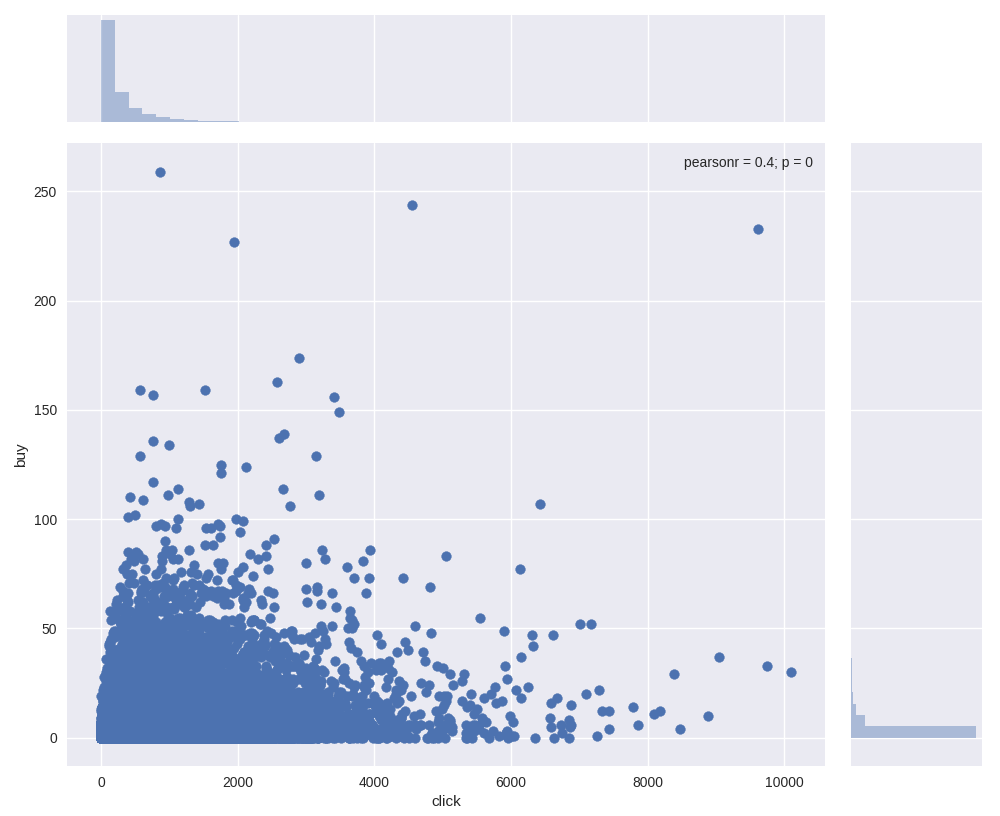
user_buy vs user_click:
item_buy vs item_click:
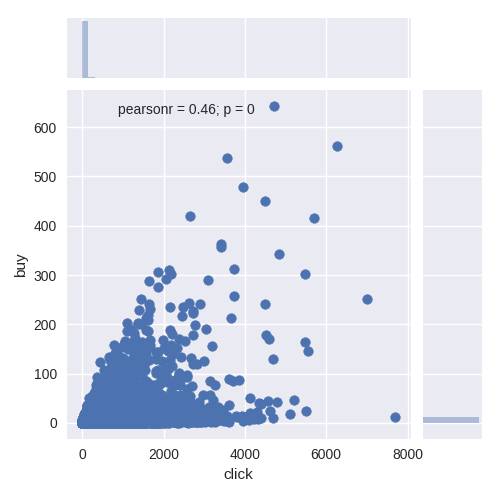
In principle, we think the user who buys or clicks too many times are unusual, they will influnce our model’s currency. We drop user or item with following rule:
For user, we select (a=6000, b=150), and (a=5000, b=300) for item.
But until now, we still can’t obtain much information of the datas. We should observe them in more points of view. At the same time, the result of operation above seems not obviously. For example, one may buy something in 1 January, but we may lost this information because our droping days before 18 February.
Split Datasets
At begining, we select all days but the last 7 to establish feature, and extract label from the last 7 days. We obtain online error with 0.41458, the best one until now. The advantage of this method is comprehensive feature data, but at the same time, the number of train data are more less.
Than we try split datasets in [feature1=(1-1, 1-30), label1=(2-1, 2-7)] and [feature2=(2-1, 2-28), label2=(3-1, 3-7)]. one of them is sended to train and the other one to valid our method. We score 0.42056 in this method, worse than the initially method.
Than we observe fig-1, we split in [feature1=(2-18, 3-18), label1=(3-19, 3-25)] and [feature2=(2-24, 3-24), label2=(3-25, 3-31)]. We are still truning our parameters and trying to select more useful feature now.
Feature Engineering
We list some useful features here:
| id | feature_name | note |
|---|---|---|
| 1 | user_click_sum | - |
| 2 | user_buy_sum | - |
| 3 | user_last_buy_to_today | - |
| 4 | user_last_click_to_today | - |
| 5 | item_click_sum | - |
| 6 | item_buy_sum | - |
| 7 | brand_click_sum | - |
| 8 | brand_buy_sum | - |
| 9 | user_click_timewindows | list |
| 10 | item_click_timewondows | list |
| 11 | brand_click_timewindows | list |
| 12 | … | others |
Model Selection
gbdt: We select Microsoft’s lightgbm to implement this algorithm, clicking here to get more information about it.
SVM: We try svc but it seems doesn’t work. The best one score about 0.67.
KNN: We use features which are same as used in gbdt, but we just score 0.53 with this method.
Truning Parameters
Turning parameters make our model get a better grade offline. But when submiting result of our prediction, it seems doesn’t work to us. Until now, we even don’t know how many num_leaves should we set.
In fact, we had attempted to turning parameter. It increase our score from 0.43 to 0.41 offline. But obviously, it doesn’t help us get a better grade when submiting.
About Others
Project Arrange
I spend about a week to explore and rebuild our working project files, and the result show that it deserves. A good strategy should guarantees:
- speed of runing. Spliting your project into some submodels is not a bad idea. For example, you can just run preparedata.py to extract feature from origin dataset and store them in specify files, and build your train.py or predict.py just like it. If you just want to add or drop one feature, you may need a new strategy to arrange your file but not abstracting from begining again and agian. What’s more, we need view the importance of our features, so you’d better named your columns with pandas DataFrame.
- expanding. Support that we need add a new algorithm to our project, we can just add one file named such as svm.py under our folder predict_algorithms if we arrange our project carefully. In fact, it has another name Design Pattern and common used in OOP.
- pipline. It’s a concept in sklearn, more information click here
Person
You have an idea, I have an idea, and exchange each other, there are two or more than two ideas. What’s more, how to arange your time still take an important part. In this contest, I cost much time to extract features and split dataset again and again even in the last several days. You need make a timetable to decide what to do in specify time. for example, your can split your work flow to explority data analysis, feature engineering, parameter turning, esemble models.
Log
The chances of submiting are limited. log your submiting file and named them with date or other importance information can help you estimate if you will get a better grade this time. Or if you has some history file which get good grade, esembling them may surprised you.
Conclusion
As we all know, the ways to improve our grades are just following:
- collect more datas to train, or make your datas more easy to learn.
- select more powerful models
- trun your paramenters
- Ensemble
The effect of them are decreasing by index. But it just likes cannikin law, you must ensure everyone of them is good enough.
And another import thing is that choose some reliable teammates. If you can’t cooperate with each other, just do it by yourself. In common, as a member of a good group, one must:
- spend time to do it
- provide idea or do something they can, even just turn parameters
- always exchange idea with other group members
It’s really upset that my friend do none of above :(.