Using tensorflow-lstm predict functions
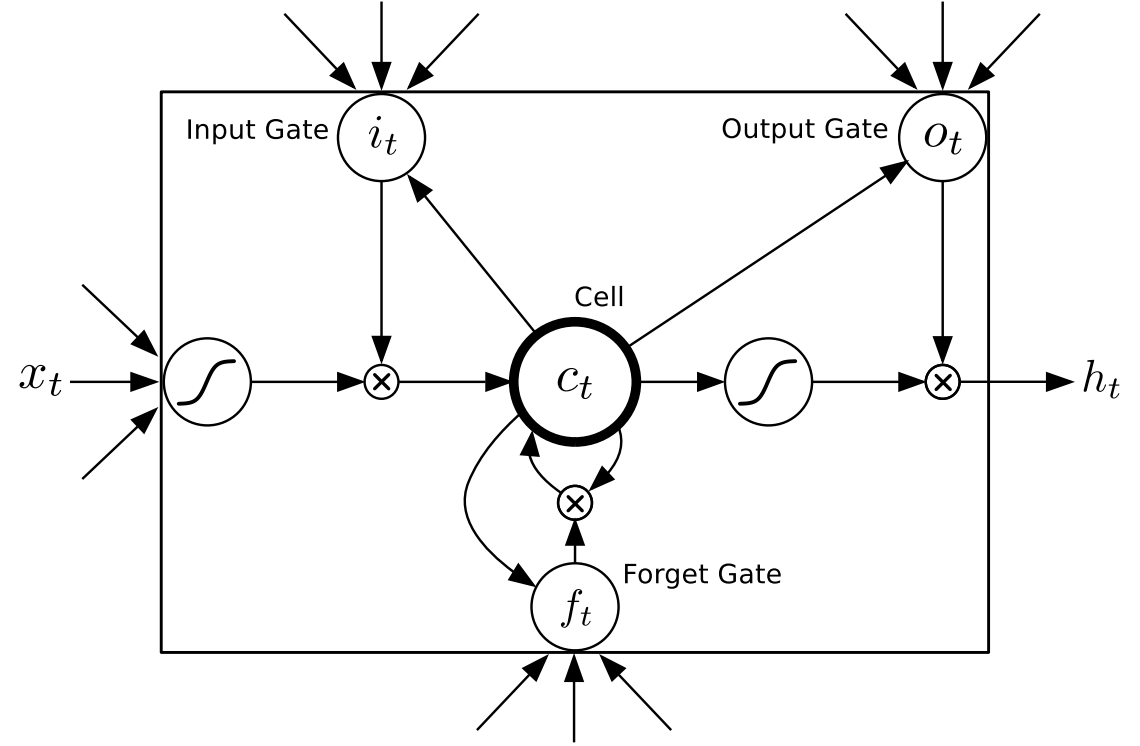
Lstm nerual network is one kind of recurrent nerual network, and usually used to predict sequences such as language. So we use it to predict some functions such as: sin(x) * k + b, and discuss the factors that influence the accuraccy of lstm.
parameters turning
base model
We firstly generate datasets which x = np.linspace(0, 20, 100), and use the first 30 values to predict the 31th one.
The toy dataset is really simple:
def f(x_array):
return list(np.sin(np.array(x_array)) * 5 + 10)
self.x = list(np.linspace(0, 20, 100))
self.y = list(f(self.x))
And than we select some parameters to make it learning from the train datasets:
config = {
"forget_bias": 1.0,
"num_units": 128,
"layers": 12,
"learning_rate": 0.1,
"epoch": 300,
"batch_size": 32,
"seq_len": 30,
"keep_prob": 0.8
}
But upseting, it’s about too many layers and large learning_rate making it learning nothing. The prediction result is:
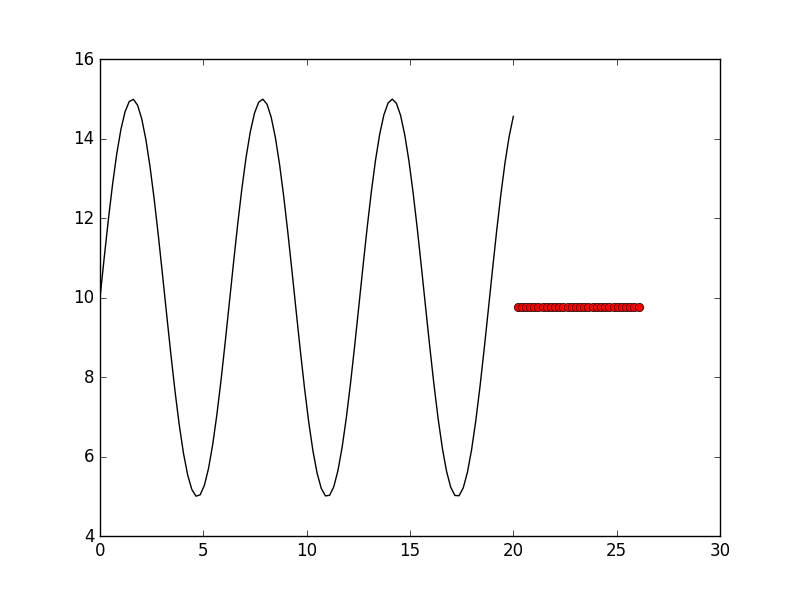
So we change the parameters above, so base model’s parameters are:
config = {
"forget_bias": 1.0,
"num_units": 128,
"layers": 2,
"learning_rate": 0.01,
"epoch": 300,
"batch_size": 32,
"seq_len": 300,
"keep_prob": 0.8
}
And the base result is:
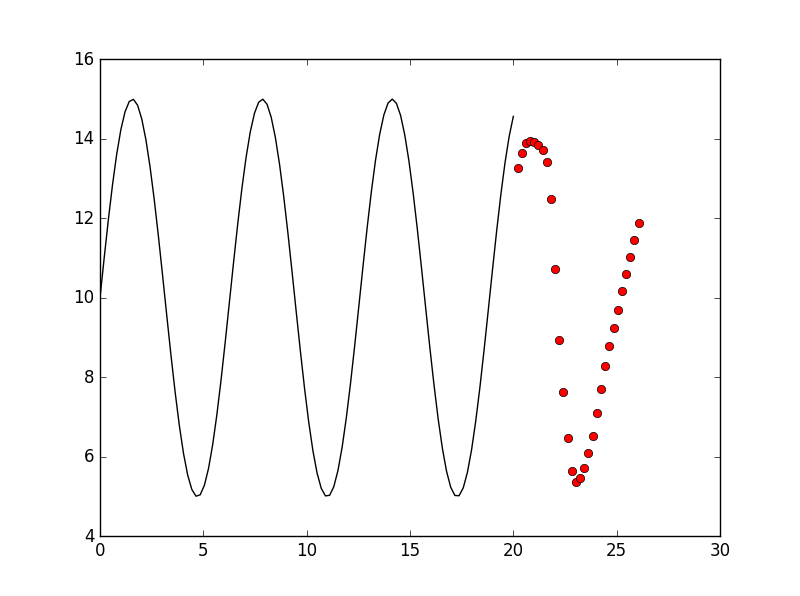
It seems better, but still don’t achieve our goal. we will improve it by kinds of ways in following.
learning_rate
We change learning_rate = 0.001, and result is:

We also try learning_rate = 0.0001, and result is:

At last, we try learning_rate = 0.00001, the result is:

So the best parameters until now seems like:
config = {
"forget_bias": 1.0,
"num_units": 128,
"layers": 2,
"learning_rate": 0.001,
"epoch": 300,
"batch_size": 32,
"seq_len": 30,
"keep_prob": 0.8
}
forget bias
The forget bias more bigger, the model will remember more about last several information pieces. We try to set it to forget_bias = 0.5, the result is:
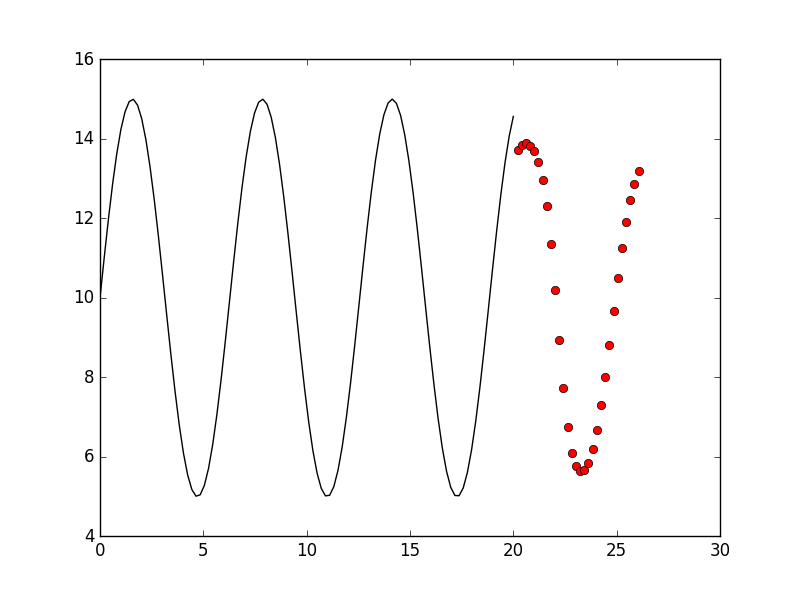
Than we also try forget_bias = 0.1
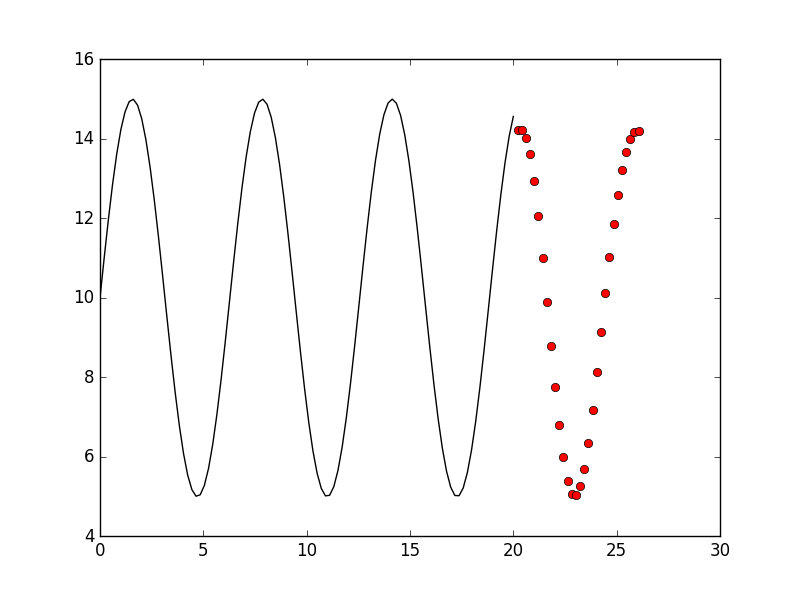
They are all not better than forget_bias = 1.0, so the best parameters still seems like:
config = {
"forget_bias": 1.0,
"num_units": 128,
"layers": 2,
"learning_rate": 0.001,
"epoch": 200,
"batch_size": 32,
"seq_len": 30,
"keep_prob": 0.8
}
layers
Now our layer is 2, but if we want improve the capacity of the model, we must add more layers. We try to set layers = 1, the result is:
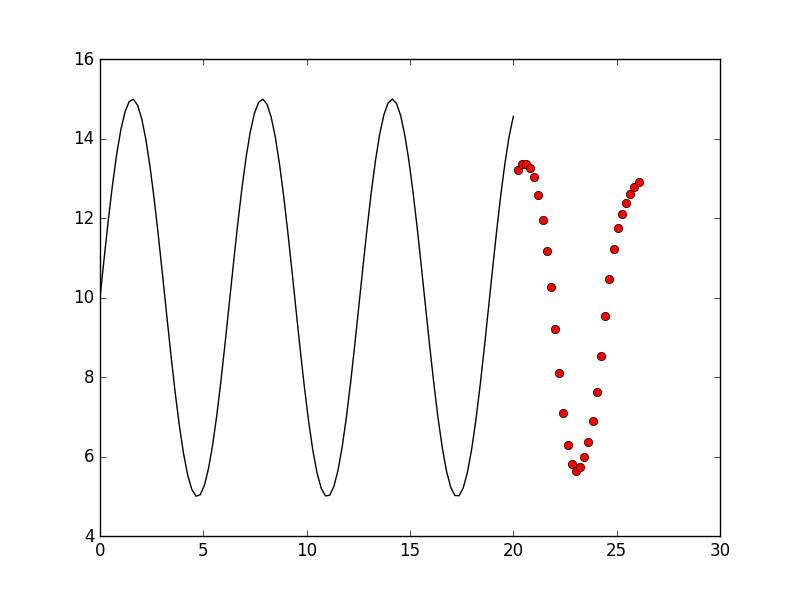
Than we try layers = 3, the result is:
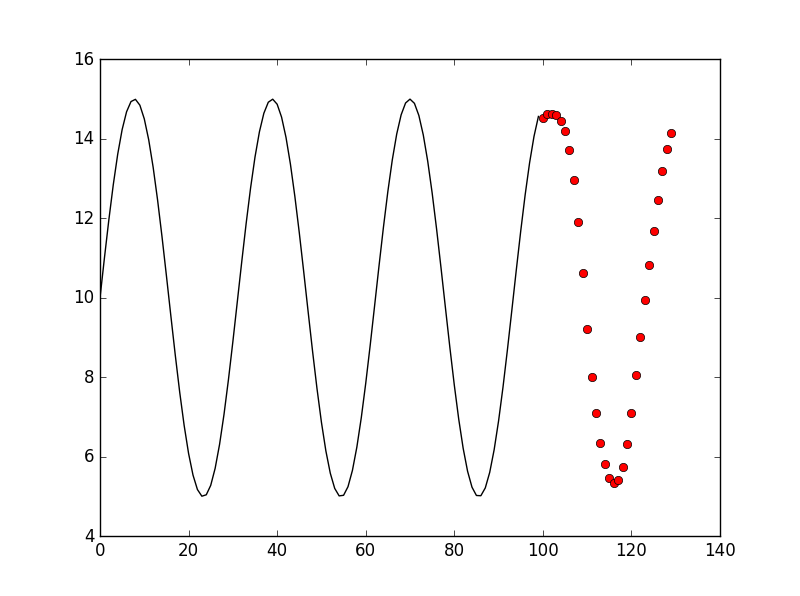
Ok, how about layers = 5?
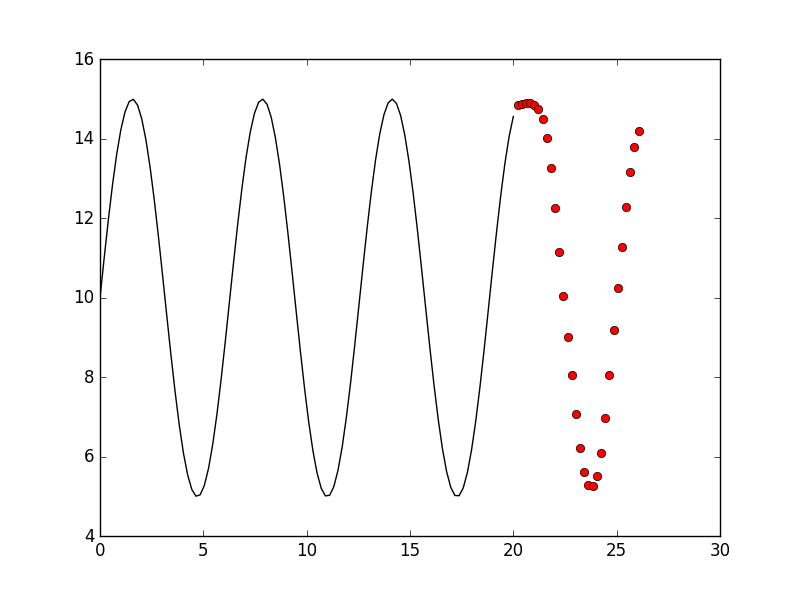
Of course, we also try more layers such as layers = 7:
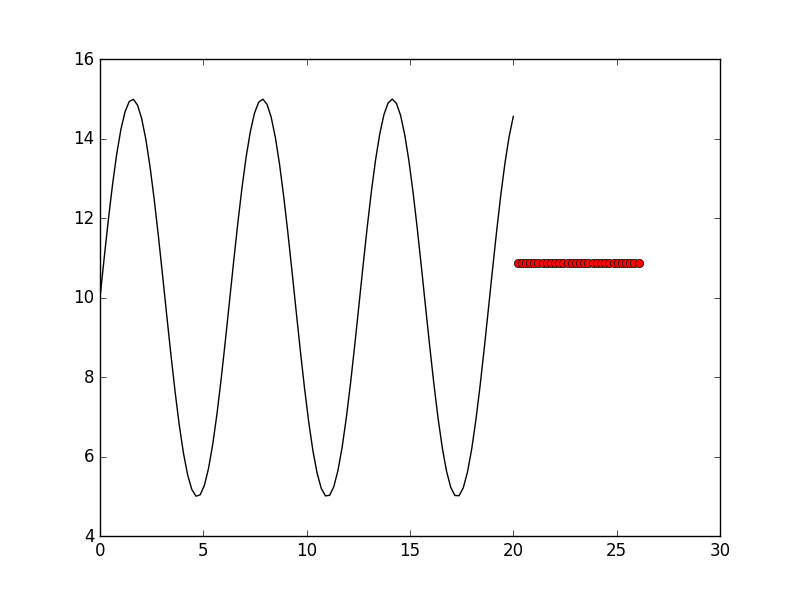
So the best parameters seems is:
config = {
"forget_bias": 1.0,
"num_units": 128,
"layers": 5,
"learning_rate": 0.001,
"epoch": 300,
"batch_size": 32,
"seq_len": 30,
"keep_prob": 0.8
}
augment dataset
Until now, we just use toy dataset to train our model. But how it will be when we use more datas to train it ?
At first, we simply add more dataset to it:
def f(x_array):
return list(np.sin(np.array(x_array)) * 5 + 10)
self.x = list(np.linspace(0, 100, 1000))
self.y = list(f(self.x))
The result seems good, but we all know that sin(x) * k + b is periodic, so we can just use part of the data to abtain good performance:
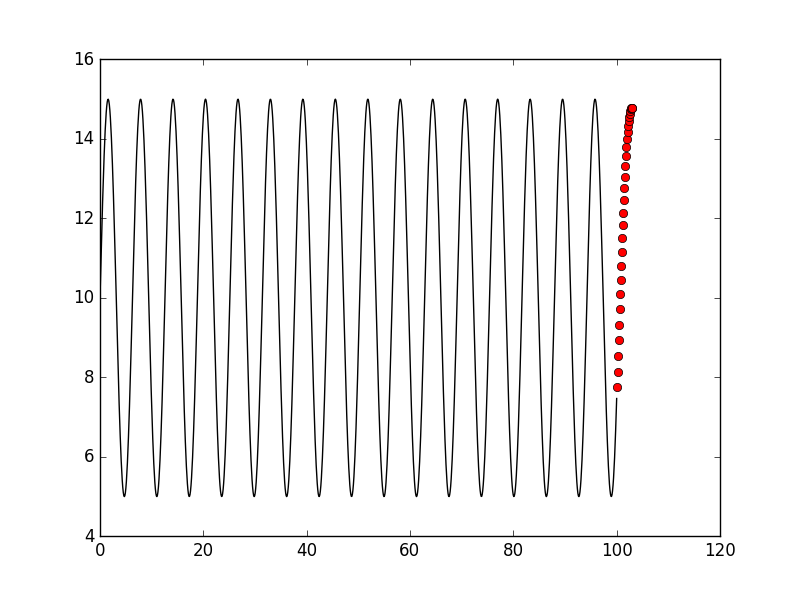
We try to imporove the std of the dataset:
def f(x_array):
return list(np.sin(np.array(x_array)) * 5 + 10. * np.array([np.random.random() for _ in range(len(x_array))]))
self.x = list(np.linspace(0, 100, 1000))
self.y = list(f(self.x))
The result is:
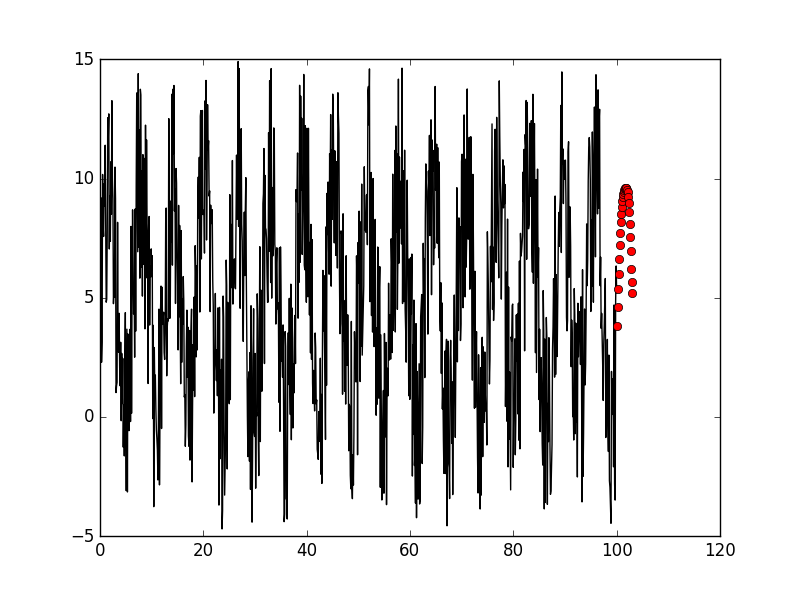
But how about other funciont? such as sin(x) * x + b * random():
def f(x_array):
return list(np.sin(np.array(x_array)) * np.array(x_array) + 10. * np.array([np.random.random() for _ in range(len(x_array))]))
self.x = list(np.linspace(0, 100, 1000))
self.y = list(f(self.x))
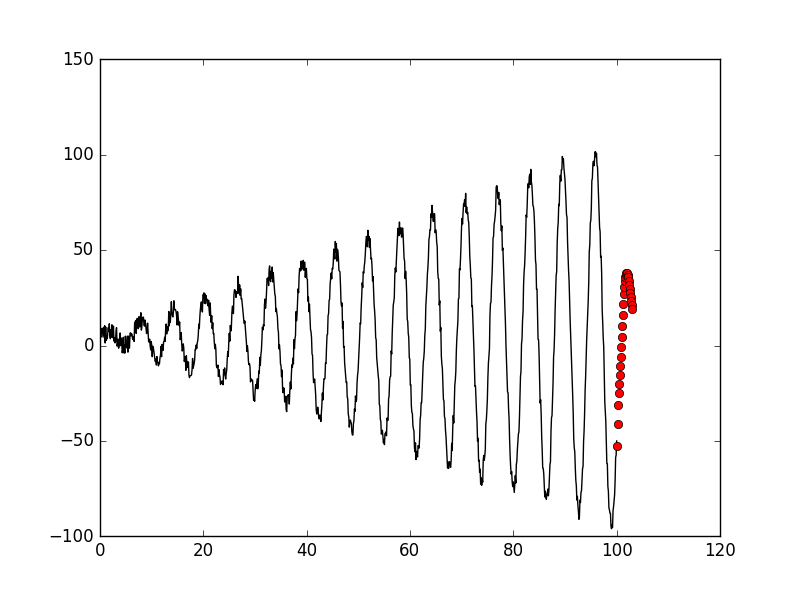
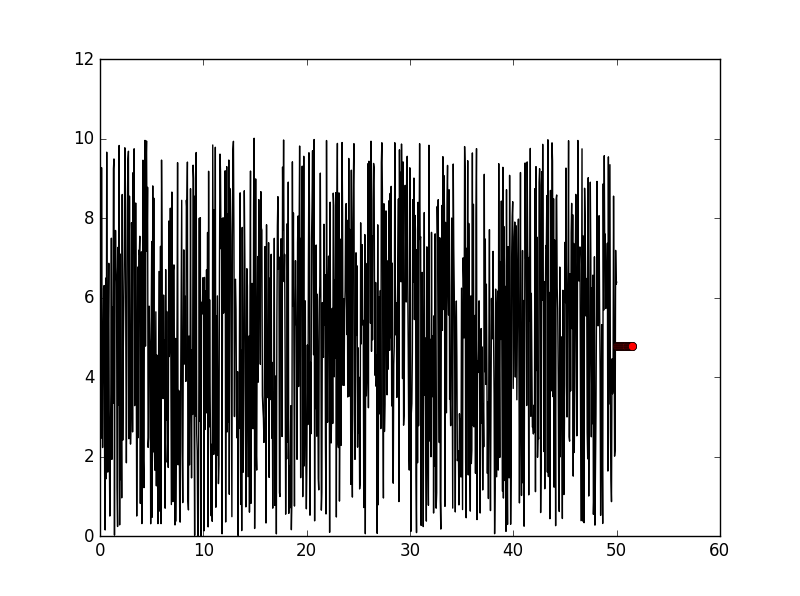
Let’s challenge more difficult:
def f(x_array):
return list(np.sin(np.array(x_array)) * np.random.random() + 10. * np.array([np.random.random() for _ in range(len(x_array))]))
self.x = list(np.linspace(0, 50, 1000))
self.y = list(f(self.x))
The result seems not good as we expected:
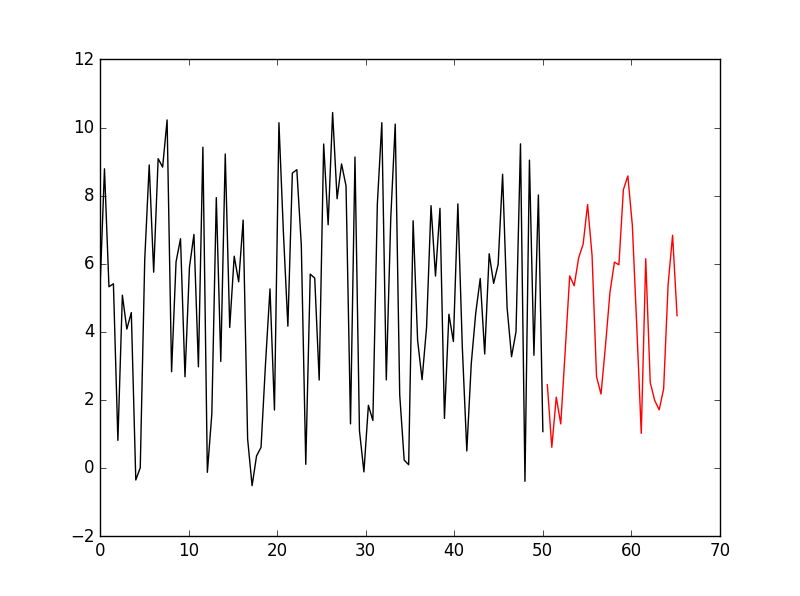
At last, we try parameters:
config = {
"forget_bias": 1.0,
"num_units": 128,
"layers": 3,
"learning_rate": 0.0001,
"epoch": 500,
"batch_size": 32,
"seq_len": 30,
"keep_prob": 1.0
}
And get a result:
souce code
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import json
import os
class DatasetUtil(object):
def __init__(self, config):
self.config = config
def f(x_array):
return list(np.sin(np.array(x_array)) * np.random.random() + 10. * np.array([np.random.random() for _ in range(len(x_array))]))
self.x = list(np.linspace(0, 50, 1000))
self.y = list(f(self.x))
self.pred_time = 0
def train_sample(self):
train_data = []
train_label = []
for _ in range(self.config['batch_size']):
start_id = int(np.random.random() * (len(self.y) - self.config['seq_len']))
train_data.append(self.y[start_id: start_id + self.config['seq_len']])
train_label.append(self.y[start_id + self.config['seq_len']])
return train_data, train_label
def predict_dataset(self):
return [self.y[-self.config['seq_len']:] for _ in range(self.config['batch_size'])]
def append_pred(self, idx_pred):
self.pred_time += 1
self.y.append(idx_pred)
sub = self.x[1] - self.x[0]
self.x.append(self.x[-1] + sub)
def plot(self):
fig, ax = plt.subplots()
ax.plot(self.x[:-self.pred_time], self.y[:-self.pred_time], 'k-')
ax.plot(self.x[-self.pred_time:], self.y[-self.pred_time:], 'ro')
plt.show()
# plt.savefig('example.png')
class LSTM(object):
def __init__(self, config):
self.config = config
self.datasetutil = DatasetUtil(config)
self.predict_result = []
def build(self):
print('############building lstm network############')
self.inputs = tf.placeholder(tf.float32, [self.config['batch_size'], self.config['seq_len']])
self.labels = tf.placeholder(tf.float32, [self.config['batch_size']])
self.keep_prob = tf.placeholder(tf.float32)
inputs = tf.expand_dims(self.inputs, -1)
labels = tf.expand_dims(self.labels, -1)
def lstm_cell():
lstmcell = tf.contrib.rnn.BasicLSTMCell(self.config['num_units'], forget_bias=self.config['forget_bias'])
lstmcell = tf.contrib.rnn.DropoutWrapper(lstmcell, input_keep_prob=self.keep_prob, output_keep_prob=self.keep_prob)
return lstmcell
mlstm_cell = tf.contrib.rnn.MultiRNNCell([lstm_cell() for _ in range(self.config['layers'])], state_is_tuple=True)
init_state = mlstm_cell.zero_state(self.config['batch_size'], dtype=tf.float32)
outputs, state = tf.nn.dynamic_rnn(mlstm_cell, inputs=inputs, initial_state=init_state)
lstm_output = outputs[:, -1, :]
W = tf.Variable(tf.random_normal([self.config['num_units'], 1], stddev=0.35))
b = tf.Variable(tf.zeros([1]))
y = tf.matmul(lstm_output, W) + b
self.result = y
self.loss = tf.reduce_sum((self.result - labels) ** 2) / self.config['batch_size']
# self.loss = tf.reduce_sum(tf.abs(self.result - labels) / labels) / self.config['batch_size']
self.train_op = tf.train.AdamOptimizer(self.config['learning_rate']).minimize(self.loss)
def fit(self):
print('############training lstm network############')
# saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(self.config['epoch']):
inputs, labels = self.datasetutil.train_sample()
result, loss, _ = sess.run([self.result, self.loss, self.train_op], feed_dict={
self.inputs: inputs, self.labels: labels, self.keep_prob: self.config['keep_prob']})
if (epoch + 1) % 50 == 0:
print('epch={}, loss={}'.format(epoch + 1, loss))
# print('inputs=', inputs)
print('result=', result)
print('labels=', labels)
for _ in range(30):
inputs = self.datasetutil.predict_dataset()
# print('predict inputs=', inputs)
[result] = sess.run([self.result], feed_dict={self.inputs: inputs, self.keep_prob: 1.0})
self.datasetutil.append_pred(result[0][0])
self.datasetutil.plot()
if __name__ == '__main__':
config = {
"forget_bias": 1.0,
"num_units": 128,
"layers": 1,
"learning_rate": 0.001,
"epoch": 500,
"batch_size": 32,
"seq_len": 30,
"keep_prob": 1.0
}
lstm = LSTM(config)
lstm.build()
lstm.fit()
enjoy :)